0.1. Motivation
After preparing for the AZ-900 for two months, I considered speed, so I reduced the amount for the next one, the data fundamentals, to a month of daily prep to finally sitting for the exam on 10 august 2021.
Data is more important today than it was yesterday as it allows people, businesses, and society to look back in time, make current decisions, and affect future outcomes.
Data can provide valuable insights.
Being aware of how it works is critical, and having a solid foundation is advantageous.
Accordingly, that's where this exam comes in handy. Discuss essential topics and terminology linked to data and cloud computing.
I still think this is a very useful exam that can lead to many exciting opportunities.
Table Of Contents
- 1. Core Data Concepts
- 2. Data Job Roles
- 3. Data Services
- 4. Relational data
- 5. Non-Relational Data
- 6. Data Analytics
- 6.1. Modern Data Warehousing
- 6.2. Real-Time Analytics
- 6.2.1. Batch Processing
- 6.2.2. Stream Processing
- 6.2.3. Elements of Stream Processing
- 6.2.4. Real-time analytics in Azure
- 6.2.5. Services for stream processing
- 6.2.6. Sinks for stream processing
- 6.2.7. Azure Stream Analytics
- 6.2.8. Apache Spark on Azure
- 6.2.9. Bonus, Delta Lake
- 6.2.10. Azure Data Explorer
- 6.3. Data Visualization
1. Core Data Concepts
1.1. Data Formats
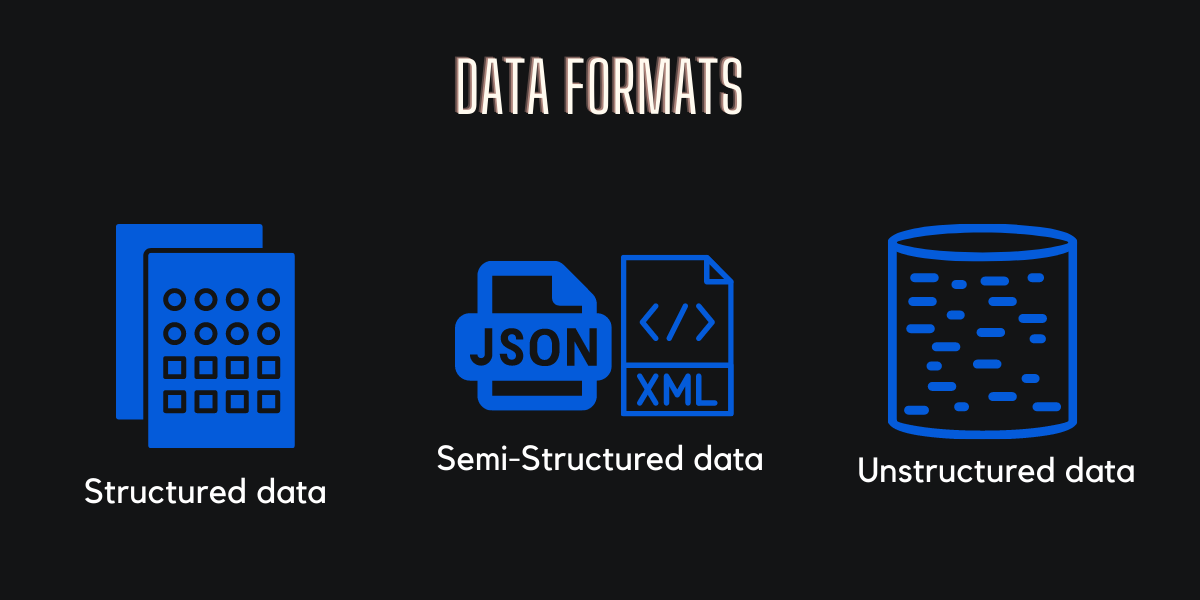
1.1.1. Structured Data
Structured data is a standardized format for providing information about a page and classifying the page content.
The schema for structured data entities is tabular - in other words, the data is represented in one or more tables that consist of rows to represent each instance of a data entity, and columns to represent attributes of the entity. This data type is generally stored in a relational database.
1.1.2. Semi-Structured Data
Semi-structured data is a form of structured data that does not obey the tabular structure of data models associated with relational databases or other forms of data tables, but nonetheless contains tags or other markers to separate semantic elements and enforce hierarchies of records and fields within the data.
Common format for semi-structured data is JSON & XML.
// Customer 1
{
"firstName": "Joe",
"lastName": "Jones",
"address":
{
"streetAddress": "1 Main St.",
"city": "New York",
"state": "NY",
"postalCode": "10099"
},
"contact":
[
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
}1.1.3. Unstructured Data
Unstructured data is information that either does not have a pre-defined data model or is not organized in a pre-defined manner. Unstructured information is typically text-heavy like, but may contain data such as dates, numbers, and facts as well.
Some examples of unstructured data: Email, Text Files, Media..
1.1.4. Data stores
A data store is a repository for persistently storing and managing collections of data which include not just repositories like databases, but also simpler store types such as simple files.
There are two broad categories of data store in common use:
File stores and Databases.
1.2. File Formats
1.2.1. Delimited text files
A delimited text file is a text file used to store data, in which each line represents a single book, company, or other thing, and each line has fields separated by the delimiter.
First_Name, Last_Name, CardNum, EmpNo, HireDate, Salary, Bonus_2011
Lila, Remlawi, 8590122497663807, 000008, 12 / 28 / 2007, 52750, '$1,405.40'
Vladimir, Alexov, 8590122281964011, 000060, 10 / 5 / 2007, 41250, '$4,557.43'
Alex, Williams, 8590124253621744, 000104, 8 / 12 / 2010, 40175, '$7,460.02'
1.2.2. JavaScript Object Notation (JSON)
JSON is an open standard file format and data interchange format that uses human-readable text to store and transmit data objects consisting of attribute–value pairs and arrays.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"variables": {
"container1name": "aci-tutorial-app",
"container1image": "mcr.microsoft.com/azuredocs/aci-helloworld:latest",
"container2name": "aci-tutorial-sidecar",
"container2image": "mcr.microsoft.com/azuredocs/aci-tutorial-sidecar"
},1.2.3. Extensible Markup Language (XML)
Extensible Markup Language, looking close to HTML syntax, is a markup language and file format for storing, transmitting, and reconstructing arbitrary data can be used in mobile developement. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable.
< LinearLayout
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="horizontal">1.2.4. Binary Large Object (BLOB)
A binary large object is a collection of binary data stored as a single entity. Blobs are typically images, audio or other multimedia objects, though sometimes binary executable code is stored as a blob.
int
main (int argc, char *argv[])
{
GdaConnection *cnc;
const gchar *filename = NULL;
gint id = 0;
gboolean store;
GError *error = NULL;
gboolean result;
/* parse arguments */
if (argc != 3)
{
goto help;
}
if (! g_ascii_strcasecmp (argv[1], "store"))
{
filename = argv[2];
store = TRUE;
}
else if (! g_ascii_strcasecmp (argv[1], "fetch"))
{
id = atoi (argv[2]);
store = FALSE;
}
else
{
goto help;
}
}1.2.5. Optimized file formats
- Avro It was created by Apache. Each record contains a header that describes the structure of the data in the record. This header is stored as JSON. The data is stored as binary information.
- ORC (Optimized Row Columnar format): Organizes data into columns rather than rows. It was developed by HortonWorks for optimizing read and write operations in Apache Hive (Hive is a data warehouse system that supports fast data summarization and querying over large datasets).
- Parquet: A columnar data format. It was created by Cloudera and Twitter. A Parquet file contains row groups. Data for each column is stored together in the same row group. Each row group contains one or more chunks of data. A Parquet file includes metadata that describes the set of rows found in each chunk.
1.3. Databases
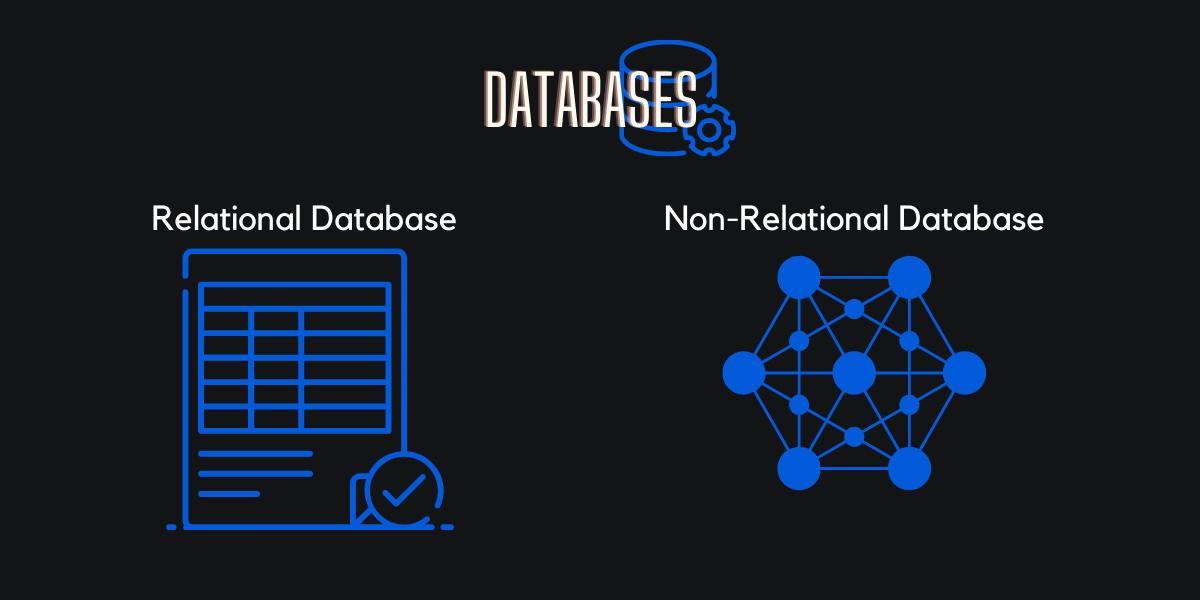
A database is an organized collection of data stored and accessed electronically. Small databases can be stored on a file system, while large databases are hosted on computer clusters or cloud storage.
1.3.1. Relational databases
A relational database is a digital database based on the relational model of data. Relational databases are commonly used to store and query structured data.
A system used to maintain relational databases is a relational database management system.
1.3.2. Non-relational databases
Non-relational databases are data management systems that don’t apply a relational schema to the data. Non-relational databases are often referred to as NoSQL database, even though some support a variant of the SQL language.
Exemple: Key-value databases, Document databases, Column family databases & Graph databases.
1.4. Transactional Data Processing
Think of a transaction as a small, discrete, unit of work. This last performed by transactional systems is often referred to as Online Transactional Processing.
OLTP solutions rely on a database system in which data storage is optimized for both read and write operations in order to support transactional workloads in which data records are created, retrieved, updated, and deleted (often referred to as CRUD operations). These operations are applied transactionally, in a way that ensures the integrity of the data stored in the database.
OLTP systems are typically used to support live applications that process business data - often referred to as line of business (LOB) applications.
1.5. Analytical Data Processing
Data analysis is the process of cleaning, changing, and processing raw data, and extracting actionable, relevant information that helps businesses make informed decisions.
Analytical data processing typically uses read-only (or read-mostly) systems that store vast volumes of historical data or business metrics. Analytics can be based on a snapshot of the data at a given point in time, or a series of snapshots.
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. This is common in modern data analytical processing scenarios, where a large volume of file-based data must be collected and analyzed.
Data Warehouse In computing, also known as an enterprise data warehouse, is a system used for reporting and data analysis and is considered a core component of business intelligence. It is an established way to store data in a relational schema that is optimized for read operations – primarily queries to support reporting and data visualization.
2. Data Job Roles
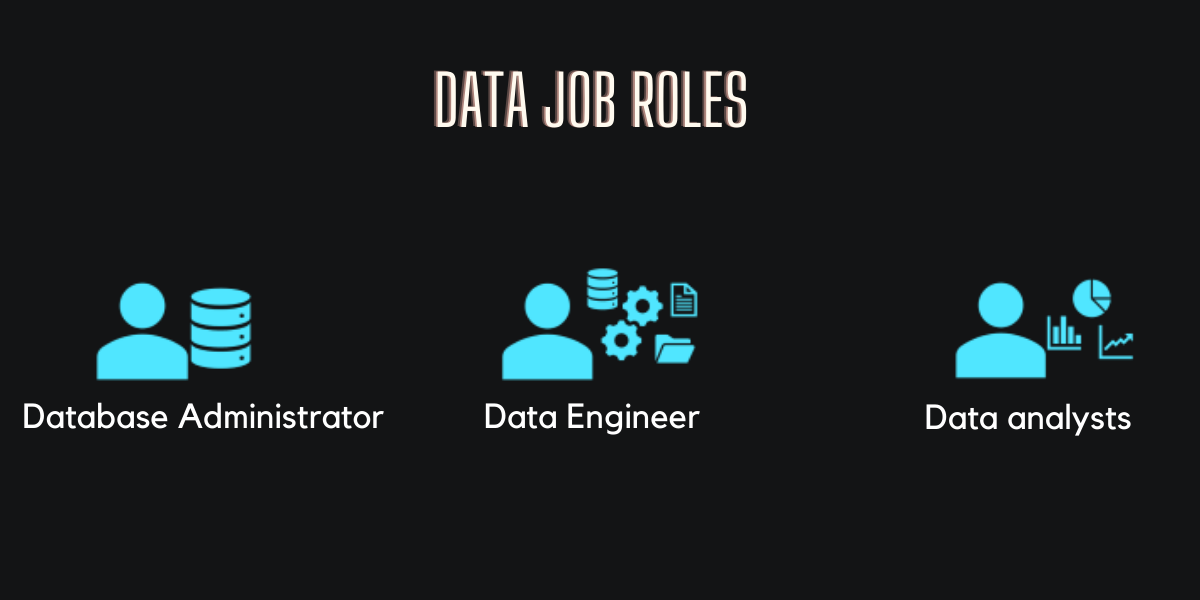
The three key job roles that deal with data in most organizations are:
2.1. Database administrators
Manage databases, assigning permissions to users, use specialized software to store and organize data. The role may include capacity planning, installation, configuration, database design, migration, performance monitoring, security, troubleshooting, as well as backup and data recovery.
2.2. Data engineers
Manage infrastructure and processes for data integration across the organization, applying data cleaning routines, identifying data governance rules, and implementing pipelines to transfer and transform data between systems.
They are responsible for designing and implementing digital databases. They use computing tools to create new databases or adjust the function and capacity of existing databases.
2.3. Data analysts
Explore and analyze data to create visualizations and charts that enable organizations to make informed decisions.
A database analyst deals with database technologies that warehouse information in very specific ways. A database analyst is part of conventional corporate IT teams that maintain data assets through very specific research and activities. A database analyst is also known as a data modeler.
3. Data Services
Microsoft Azure is a cloud platform that powers the applications and IT infrastructure for some of the world's largest organizations. It includes many services to support cloud solutions, including transactional and analytical data workloads.
3.1. Azure SQL
What's SQL? SQL is a domain-specific language used in programming and designed for managing data held in a relational database management system, or for stream processing in a relational data stream management system.
Azure SQL is the collective name for a family of relational database solutions based on the Microsoft SQL Server database engine.
Specific Azure SQL services include:
- Azure SQL Database: A fully managed platform-as-a-service (PaaS) database hosted in Azure
- Azure SQL Managed Instance: A hosted instance of SQL Server with automated maintenance, which allows more flexible configuration than Azure SQL DB but with more administrative responsibility for the owner.
- Azure SQL VM: A virtual machine with an installation of SQL Server, allowing maximum configurability with full management responsibility.
3.2. Azure Database for open-source relational databases
Azure Database is a fully managed platform as a service (PaaS) database engine that handles most of the database management functions such as upgrading, patching, backups, and monitoring without user involvement. Azure includes managed services for popular open-source relational database systems
Azure Database for MySQL: A simple-to-use open-source database management system that is commonly used in Linux, Apache, MySQL, and PHP (LAMP) stack apps.
Azure Database for MariaDB: A newer database management system, created by the original developers of MySQL. The database engine has since been rewritten and optimized to improve performance. MariaDB offers compatibility with Oracle Database (another popular commercial database management system).
Azure Database for PostgreSQL: A hybrid relational-object database. You can store data in relational tables, but a PostgreSQL database also enables you to store custom data types, with their own non-relational properties.
3.3. Azure Cosmos DB
Azure Cosmos DB is Microsoft's proprietary globally distributed, multi-model database service "for managing data at planet-scale" launched in May 2017. It is schema-agnostic, horizontally scalable, and generally classified as a NoSQL database.
3.4. Azure Storage
Azure Storage is a core Azure service that enables you to store data in:
- Blob containers - scalable, cost-effective storage for binary files.
- File shares - network file shares such as you typically find in corporate networks.
- Tables - key-value storage for applications that need to read and write data values quickly.
3.5. Azure Data Factory
Azure Data Factory is the platform that solves such data scenarios. It is the cloud-based ETL and data integration service that allows you to create data-driven workflows for orchestrating data movement and transforming data at scale
3.6. Azure Synapse Analytics
Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing, and big data analytics. It gives you the freedom to query data on your terms, using either serverless or dedicated options at scale.
3.7. Azure HDInsight
Azure HDInsight is a managed, full-spectrum, open-source analytics service in the cloud for enterprises. With HDInsight, provides Azure-hosted clusters open-source frameworks such as Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm, R, and more, in your Azure environment.
3.8. Azure Stream Analytics
Microsoft Azure Stream Analytics is a serverless scalable complex event processing engine by Microsoft that enables users to develop and run real-time analytics on multiple streams of data from sources such as devices, sensors, web sites, social media, and other applications
3.9. Azure Data Explorer
Azure Data Explorer is a fully-managed big data analytics cloud platform and data-exploration service, developed by Microsoft, that ingests structured, semi-structured and unstructured data. The service then stores this data and answers analytic ad hoc queries on it with seconds of latency.
3.10. Azure Purview
Azure Purview, which is currently in preview, is a long-awaited tool from Microsoft that is designed to provide a solution for centralized data governance for an organization's entire environment, including on-premises databases, cloud databases, SaaS data, and virtually any other data source or platform.
3.11. Microsoft Power BI
Power BI is an interactive data visualization software product developed by Microsoft with primary focus on business intelligence. It is part of the Microsoft Power Platform. Power BI reports can be created by using the Power BI Desktop application, and the published and delivered through web-based reports and apps in the Power BI service, as well as in the Power BI mobile app.
4. Relational data
4.1. Relational Data Concepts
4.1.1. Understand normalization
Normalization is a term used by database professionals for a schema design process that minimizes data duplication and enforces data integrity.
Database normalization is the process of structuring a database, usually a relational database, in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by Edgar F. Codd as part of his relational model.
Normalization entails organizing the columns (attributes) and tables (relations) of a database to ensure that their dependencies are properly enforced by database integrity constraints. It is accomplished by applying some formal rules either by a process of synthesis (creating a new database design) or decomposition (improving an existing database design).
4.1.2. SQL dive
SQL stands for Structured Query Language, and is used to communicate with a relational database. It's the standard language for relational database management systems. SQL statements are used to perform tasks such as update data in a database, or retrieve data from a database. Some common relational database management systems that use SQL include Microsoft SQL Server, MySQL, PostgreSQL, MariaDB, and Oracle.
SQL commands such as SELECT, INSERT, UPDATE, DELETE, CREATE, and DROP can be used to accomplish practically any task with a database. Despite the fact that these SQL statements are part of the SQL standard, many database management systems have their own proprietary extensions to handle the system's characteristics. These extensions add functionality to SQL that isn't covered by the standard, such as security management and programmability.
SQL statements are grouped into three main logical groups:
Data Definition Language (DDL): You use DDL statements to create, modify, and remove tables and other objects in a database (table, stored procedures, views, and so on).
CREATE TABLE Product( ID INT PRIMARY KEY, Name VARCHAR(20) NOT NULL, Price DECIMAL NULL);Data Control Language (DCL): Database administrators generally use DCL statements to manage access to objects in a database by granting, denying, or revoking permissions to specific users or groups.
GRANT SELECT, INSERT, UPDATEON ProductTO user1;Data Manipulation Language (DML): You use DML statements to manipulate the rows in tables. SELECT, INSERT, UPDATE, DELETE.
SELECT *FROM CustomerWHERE City = 'Seattle';INSERT INTO Product(ID, Name, Price)VALUES (99, 'Drill', 4.99);4.1.3. Database Objects
4.1.3.1. Database View
A database view is a subset of a database and is based on a query that runs on one or more database tables. Database views are saved in the database as named queries and can be used to save frequently used, complex queries. There are two types of database views: dynamic views and static views.
CREATE VIEW DeliveriesASSELECT o.OrderNo, o.OrderDate, c.FirstName, c.LastName, c.Address, c.CityFROM Order AS o JOIN Customer AS cON o.CustomerID = c.ID;4.1.3.2. Stored Procedure
A stored procedure is a set of Structured Query Language (SQL) statements with an assigned name, which are stored in a relational database management system (RDBMS) as a group, so it can be reused and shared by multiple programs.
CREATE PROCEDURE RenameProduct @ProductID INT, @NewName VARCHAR(20)ASUPDATE ProductSET Name = @NewNameWHERE ID = @ProductID;4.1.3.3. Index
An index helps you search for data in a table. Think of an index over a table like an index at the back of a book. A book index contains a sorted set of references, with the pages on which each reference occurs. When you want to find a reference to an item in the book, you look it up through the index. You can use the page numbers in the index to go directly to the correct pages in the book. Without an index, you might have to read through the entire book to find the references you're looking for.
CREATE INDEX idx_ProductNameON Product(Name);4.2. Relational Database Services
4.2.1. Azure SQL services
4.2.1.1. SQL Server on Azure VMs (IaaS)
SQL Server running on an Azure virtual machine effectively replicates the database running on real on-premises hardware. Migrating from the system running on-premises to an Azure virtual machine is no different than moving the databases from one on-premises server to another.
Use this option when you need to migrate or extend an on-premises SQL Server solution and retain full control over all aspects of server and database configuration.
4.2.1.2. Azure SQL Managed Instance (PaaS)
Azure SQL Managed instance effectively runs a fully controllable instance of SQL Server in the cloud. You can install multiple databases on the same instance. You have complete control over this instance, much as you would for an on-premises server. SQL Managed Instance automates backups, software patching, database monitoring, and other general tasks, but you have full control over security and resource allocation for your databases.
Use this option for most cloud migration scenarios, particularly when you need minimal changes to existing applications.
4.2.1.3. Azure SQL Database ( PaaS)
Azure SQL Database is a PaaS offering from Microsoft. You create a managed database server in the cloud, and then deploy your databases on this server. Azure SQL Database is available as a Single Database or an Elastic Pool.
Single Database: This option enables you to quickly set up and run a single SQL Server database. You create and run a database server in the cloud, and you access your database through this server.
Elastic Pool: This option is similar to Single Database, except that by default multiple databases can share the same resources, such as memory, data storage space, and processing power through multiple-tenancy.
Use this option for new cloud solutions, or to migrate applications that have minimal instance-level dependencies.
4.2.2. Open-Source Databases
MySQL, MariaDB, and PostgreSQL are relational database management systems that are tailored for different specializations.
4.2.2.1. MySQL
It started life as a simple-to-use open-source database management system. It's the leading open source relational database for Linux, Apache, MySQL, and PHP (LAMP) stack apps. It's available in several editions; Community, Standard, and Enterprise. The Community edition is available free-of-charge, and has historically been popular as a database management system for web applications, running under Linux. Versions are also available for Windows. Standard edition offers higher performance, and uses a different technology for storing data. Enterprise edition provides a comprehensive set of tools and features, including enhanced security, availability, and scalability. The Standard and Enterprise editions are the versions most frequently used by commercial organizations, although these versions of the software aren't free.
Azure Database for MySQL Flexible Server: MySQL in Azure Database Flexible Server is a fully managed database as a service with predictable performance and scalability. Database management functions and configuration settings are more granularly controlled and flexible with Flexible Server. All new developments or migrations should use the flexible server deployment option.
Azure Database for MySQL Single Server: MySQL in Azure Database Single Server is a fully managed database as a service with predictable performance and scalability. Single servers are ideal for applications that are already running on a single server.
4.2.2.2. MariaDB
It is a newer database management system, created by the original developers of MySQL. The database engine has since been rewritten and optimized to improve performance. MariaDB offers compatibility with Oracle Database (another popular commercial database management system). One notable feature of MariaDB is its built-in support for temporal data. A table can hold several versions of data, enabling an application to query the data as it appeared at some point in the past.
4.2.2.3. PostgreSQL
It is a hybrid relational-object database. You can store data in relational tables, but a PostgreSQL database also enables you to store custom data types, with their own non-relational properties. The database management system is extensible; you can add code modules to the database, which can be run by queries. Another key feature is the ability to store and manipulate geometric data, such as lines, circles, and polygons.
PostgreSQL has its own query language called pgsql. This language is a variant of the standard relational query language, SQL, with features that enable you to write stored procedures that run inside the database.
Azure Database for PostgreSQL Single Server: The single-server deployment option for PostgreSQL provides similar benefits as Azure Database for MySQL. You choose from three pricing tiers: Basic, General Purpose, and Memory Optimized. Each tier supports different numbers of CPUs, memory, and storage sizes; you select one based on the load you expect to support.
Azure Database for PostgreSQL Flexible Server: The flexible-server deployment option for PostgreSQL is a fully managed database service. It provides more control and server configuration customizations, and has better cost optimization controls.
Azure Database for PostgreSQL Hyperscale (Citus): Hyperscale (Citus) is a deployment option that scales queries across multiple server nodes to support large database loads. Your database is split across nodes.
5. Non-Relational Data
5.1. Azure Storage
The Azure Storage platform is Microsoft's cloud storage solution for modern data storage scenarios.
5.1.1. Azure blob storage
Azure Blob Storage is a service that lets you store vast volumes of unstructured data in the cloud as binary large objects (blobs). Blobs are a quick and easy way to store data files in a cloud-based format, and applications may read and write them using the Azure blob storage API.
Blobs are stored in containers in an Azure storage account. A container is a useful tool for collecting together related blobs. At the container level, you have control over who can read and write blobs.
5.1.1.1. Azure Blob Storage Types
Block blobs: A block blob is treated like a collection of blocks. Each block can be up to 100 MB in size. A block blob can hold up to 50,000 blocks, with a maximum capacity of more than 4.7 TB.
Page blobs: A page blob is a group of 512-byte pages of set size. A page blob is designed to handle random read and write operations; if necessary, you can obtain and save data for a single page. A page blob has the capacity to store up to 8 TB of data. Azure implements virtual disk storage for virtual machines using page blobs.
Append blobs: A block blob optimized for append operations is known as an append blob. Only new blocks can be added to the end of an append blob; existing blocks cannot be updated or deleted. Each block can be up to 4 MB in size. An add blob can be little over 195 GB in size.
5.1.1.2. Azure Blob Storage Access Tiers
Hot: It is the default setting. This layer is for blobs that are often accessed. The blob data is kept on high-capacity media.
Cool: When opposed to the Hot tier, it has inferior performance and lower storage costs. For data that is viewed seldom, use the Cool tier. Newly formed blobs are frequently accessed at first, but less frequently as time passes. You can build the blob in the Hot tier in these cases, then transfer it to the Cool tier afterwards. A blob can be migrated from the Cool tier to the Hot tier.
Archive: It provides the cheapest storage, but at the penalty of higher latency. The Archive tier is for historical data that must not be lost but is only needed on rare occasions. The Archive tier stores blobs in a state that is effectively offline. Reading latency for the Hot and Cool tiers is typically a few milliseconds, whereas data availability for the Archive layer can take hours.
5.1.2. Azure DataLake Storage Gen
The Azure Data Lake Store (Gen1) service is a distinct service for hierarchical data storage for analytical data lakes, which is frequently utilized by so-called big data analytical solutions that work with structured, semi-structured, and unstructured data stored in files. Azure Data Lake Storage Gen2 is a newer version of this service that is integrated into Azure Storage, allowing you to take advantage of the scalability of blob storage and the cost-control of storage tiers, as well as the hierarchical file system capabilities and compatibility with major analytics systems.
Systems such as Hadoop in Azure HDInsight, Azure Databricks, and Azure Synapse Analytics can leverage a distributed file system stored in Azure Data Lake Store Gen2 to process massive amounts of data.
5.1.3. Azure Files
File shares are used in many on-premises systems that consist of a network of in-house computers. A file sharing allows you to keep a file on one computer and give users and apps on other machines access to it. This method works well for computers on the same local area network, but it doesn't scale well when the number of users grows or if users are spread out over multiple locations.
Azure Data is simply a mechanism to construct cloud-based network shares, similar to those used in on-premises companies to share documents and other files across different users. By hosting file shares on Azure, businesses may save money on hardware and maintenance while also getting high-availability and scalable cloud storage for their files.
5.1.3.1. Azure File Storage Performance Tiers
Standard Tier: uses hard disk-based hardware in a datacenter
Premium Tier: uses solid-state disks. It offers greater throughput, but is charged at a higher rate.
5.1.3.2. Supported Protocols
Server Message Block (SMB) file sharing: commonly used across multiple operating systems (Windows, Linux, macOS).
Network File System (NFS) shares: used by some Linux and macOS versions. To create an NFS share, you must use a premium tier storage account and create and configure a virtual network through which access to the share can be controlled.
5.1.4. Azure Tables
Table Storage in Azure is a NoSQL storage solution that uses tables to store key/value data elements. Each item is represented by a row with columns containing the data fields that must be stored.
Azure Table Storage divides a table into partitions to assist assure rapid access. Partitioning is a method of putting related rows together based on a shared property or partition key. Rows with the same partition key will be grouped together in the database. Partitioning can help with data organization as well as scalability and performance in the following ways:
- Partitions are self-contained and can expand or contract as rows are added to or removed from a partition. A table can have as many partitions as it wants.
- You can include the partition key in the search criteria while looking for data. This reduces the number of I/O (input and output operations, or reads and writes) required to identify the data, which helps to reduce the volume of data to be analyzed and improves speed.
5.2. Azure Cosmos DB
5.2.0.1. what is an API?
An API is an Application Programming Interface. Database management systems (and other software frameworks) provide a set of APIs that developers can use to write programs that need to access data. The APIs vary for different database management systems.
5.2.1. Outline Cosmos DB
Multiple application programming interfaces (APIs) are available in Azure Cosmos DB, allowing developers to work with data in a Cosmos DB database using the programming semantics of many different types of data stores. Developers may use Cosmos DB to store and query data using APIs they're already familiar with because the internal data structure has been abstracted.
Cosmos DB is a database management system that is extremely scalable. Your partitions are automatically allocated space in a container by Cosmos DB, and each partition can grow to a maximum capacity of 10 GB. Indexes are automatically established and maintained. There isn't much in the way of administrative overhead.
5.2.1.1. Cosmos DB USE-CASE
- IoT and telematics: Large volumes of data are generally ingested in short bursts by these systems. Cosmos DB can easily receive and store this data. Analytics services like Azure Machine Learning, Azure HDInsight, and Power BI may then utilise the data. You may also process data in real time using Azure Functions, which are triggered when data is entered into the database.
- Retail and marketing: Cosmos DB is used by Microsoft for its own e-commerce services, which are integrated into Windows Store and Xbox Live. In the retail industry, it's also used for catalog data storage and event sourcing in order processing pipelines.
- Gaming: The database tier is an important part of any gaming application. Modern games use mobile/console clients for graphical processing, but the cloud is used to send customized and personalized material such as in-game metrics, social media integration, and high-score leaderboards. To deliver an interesting in-game experience, games frequently require single-millisecond read and write latencies. During new game releases and feature upgrades, a gaming database must be fast and able to handle significant surges in request rates.
- Web and mobile applications: Azure Cosmos DB is a popular database for modeling social interactions, interacting with third-party services, and creating rich personalized experiences in web and mobile applications. Using the popular Xamarin framework, the Cosmos DB SDKs may be utilized to create complex iOS and Android applications.
5.2.2. Azure Cosmos DB Supported APIs
5.2.2.1. Core (SQL) API
Despite being a NoSQL data storage system, Cosmos DB's native API manages data in JSON document format and employs SQL syntax to deal with it.
One or more JSON documents are returned as a result of this query, as demonstrated here:SELECT *FROM customers cWHERE c.id = "joe@litware.com"{ "id": "joe@litware.com", "name": "Joe Jones", "address": { "street": "1 Main St.", "city": "Seattle" } }
5.2.2.2. MongoDB API
MongoDB is a popular open source database that uses the Binary JSON (BSON) format to store data. The MongoDB API allows developers to work with data in Azure Cosmos DB using MongoDB client libraries and code.
The MongoDB Query Language (MQL) has a simple, object-oriented syntax that allows developers to call methods using objects. The find method is used in the following query to query the products collection in the database object:
db.products.find({id: 123})This query returns JSON documents that look something like this:
{ "id": 123, "name": "Hammer", "price": 2.99}}5.2.2.3. Table API
Similar to Azure Table Storage, the Table API is used to work with data in key-value tables. Compared to Azure Table Storage, the Azure Cosmos DB Table API provides more scalability and performance.
For example, you could create a table called Customers as follows:
| PartitionKey | RowKey | Name | |
|---|---|---|---|
| 1 | 123 | Joe Jones | joe@litware.com |
| 1 | 124 | Samir Nadoye | samir@northwind.com |
You may then make calls to your service endpoint using the Cosmos DB Table API via one of the language-specific SDKs to retrieve data from the table. For example, the following request retrieves the row in the table above that contains the record for Samir Nadoy:
https://endpoint/Customers(PartitionKey='1',RowKey='124')5.2.2.4. Cassandra API
The Cassandra API enables you to interact with data stored in Azure Cosmos DB using the Cassandra Query Language (CQL) , Cassandra-based tools (like cqlsh) and Cassandra client drivers that you're already familiar with. The serverless capacity mode is now available on Azure Cosmos DB's Cassandra API.
The Cassandra API is compatible with Apache Cassandra, a prominent open source database that stores data in column families. Column families are tables that are similar to those in a relational database, except that every row does not have to have the same columns.
| ID | Name | Manager |
|---|---|---|
| 1 | Sue Smith | |
| 2 | Ben Chan | Sue Smith |
Cassandra supports a syntax based on SQL, so a client application could retrieve the record for Ben Chan like this:
SELECT * FROM Employees WHERE ID = 25.2.2.5. Gremlin API
It is a multi-model database and supports document, key-value, graph, and column-family data models. Azure Cosmos DB provides a graph database service via the Gremlin API on a fully managed database service designed for any scale.
Entities are specified as vertices that form nodes in a connected graph, and the Gremlin API is used with data in a graph structure. Edges connect nodes and represent relationships
Gremlin syntax includes functions to operate on vertices and edges, enabling you to insert, update, delete, and query data in the graph. For example, you could use the following code to add a new employee named Alice that reports to the employee with ID 1
g.addV('employee')
.property('id', '3')
.property('firstName', 'Alice')
g.V('3')
.addE('reports to')
.to(g.V('1'))
RESULTS
g.V()
.hasLabel('employee')
.order()
.by('id')
6. Data Analytics
A data warehouse is a type of data management system that is designed to enable and support business intelligence (BI) activities, especially analytics. Data warehouses are solely intended to perform queries and analysis and often contain large amounts of historical data.
6.1. Modern Data Warehousing
The architecture of modern data warehousing can vary, as can the technology used to achieve it; nonetheless, the following features are typically included:
6.1.0.1. Data ingestion and processing
Data is fed into a data lake or a relational data warehouse from one or more transactional data stores, files, real-time streams, or other sources. The data is cleaned, filtered, and restructured for analysis during the load procedure using an extract, transform, and load (ETL) or extract, load, and transform (ELT) method.
6.1.0.2. Analytical data store
Relational data warehouses, file-system based data lakes, and hybrid architectures that mix aspects of data warehouses and data lakes are examples of data warehourses for large-scale data store (sometimes called data lakehouses or lake databases)
6.1.0.3. Analytical data model
While data analysts and data scientists can work directly with the data in the analytical data store, it's typical to develop one or more data models that pre-aggregate the data to make reports, dashboards, and interactive visualizations easier to produce.
6.1.0.4. Data visualization
data analysts consume data from analytical models, and directly from analytical stores to create reports, dashboards, and other visualizations. Additionally, users in an organization who may not be technology professionals might perform self-service data analysis and reporting.
6.1.1. Data Ingestion Pipelines
A data ingestion pipeline moves streaming data and batched data from pre-existing databases and data warehouses to a data lake. Businesses with big data configure their data ingestion pipelines to structure their data, enabling querying using SQL-like language.
6.1.2. Analytical Data Stores
Analytical data stores can be divided into two common categories.
6.1.2.1. Data warehouses
A data warehouse is a relational database with a schema that is intended for data analytics rather than transactional workloads. Data from a transactional database is commonly denormalized into a schema in which numeric values are stored in central fact tables, which are linked to one or more dimension tables that represent entities that can be aggregated. A fact table might, for example, contain sales order data that can be grouped by client, product, store, and time (enabling you, for example, to easily find monthly total sales revenue by product for each store).
6.1.2.2. Data lakes
A data lake is a file repository for high-performance data access, typically on a distributed file system. To process queries on the stored files and return data for reporting and analytics, technologies like Spark or Hadoop are frequently employed. These systems frequently use a schema-on-read technique to create tabular schemas on semi-structured data files as they are read for analysis, rather than imposing limitations when the data is saved. Data lakes are ideal for storing and analyzing a variety of structured, semi-structured, and unstructured data without the need for schema enforcement when the data is written to the store.
You can use a hybrid approach that combines features of data lakes and data warehouses in a lake database or data lakehouse.
6.1.3. Azure services for Analytical Stores
6.1.3.1. Azure Synapse Analytics
Azure Synapse Analytics is a comprehensive, end-to-end data analytics solution for huge data sets. It combines a scalable, high-performance SQL Server-based relational data warehouse with the flexibility of a data lake and open-source Apache Spark, allowing you to combine the data integrity and reliability of a relational data warehouse with the flexibility of a data lake and open-source Apache Spark. It also has built-in data pipelines for data intake and transformation, as well as native support for log and telemetry analytics with Azure Synapse Data Explorer pools. All Azure Synapse Analytics services are handled through Azure Synapse Studio, a single, interactive user interface that includes the ability to build interactive notebooks that blend Spark code and markdown content. When you want to develop something unique, Synapse Analytics is a terrific option.
6.1.3.2. Azure Databricks
The popular Databricks platform is now available on Azure as Azure Databricks. Databricks is a comprehensive data analytics and data science solution built on Apache Spark that includes native SQL capabilities as well as workload-optimized Spark clusters. Databricks has an interactive user interface that allows you to administer the system and analyze data in interactive notebooks. If you wish to employ existing experience with the platform or if you need to operate in a multi-cloud environment or offer a cloud-portable solution, you might want to consider using Azure Databricks as your analytical store due to its widespread use on many cloud platforms.
6.1.3.3. Azure HDInsight
It is an Azure service that supports several different types of open-source data analytics clusters. Although it is not as user-friendly as Azure Synapse Analytics and Azure Databricks, it is a viable alternative if your analytics solution is built on numerous open-source frameworks or if you need to migrate an on-premises Hadoop-based solution to the cloud.
6.2. Real-Time Analytics
6.2.1. Batch Processing
6.2.1.1. What is that
Multiple data records are collected and stored before being processed in a single operation, which is known as batch processing.
6.2.1.2. Sample
Newly arriving data pieces are collected and stored in batch processing, and the entire group is processed as a batch. There are several approaches to identify when each group is processed. You can, for example, process data on a regular basis (every hour), or when a given volume of data arrives, or as a result of some other occurrence.
6.2.2. Stream Processing
6.2.2.1. What is that
Stream processing is a method of continuously monitoring and processing a data source in real time as new data events occur.
6.2.2.2. Sample
Each new piece of data is processed as it arrives in stream processing. Unlike batch processing, there is no need to wait for the next batch processing period because data is processed in real-time as individual units rather than in batches. In cases where new, dynamic data is generated on a regular basis, stream data processing is advantageous.
6.2.2.3. Da Combination
A combination of batch and stream processing is used in many large-scale analytics applications, allowing for both historical and real-time data analysis. Stream processing solutions frequently capture real-time data, process it by filtering or aggregating it, and present it through real-time dashboards and visualizations (for example, showing the running total of cars that have passed along a road in the last hour), all while persisting the processed results in a data store for historical analysis alongside batch processed data (for example, to enable analysis of traffic volumes over the past year).
6.2.3. Elements of Stream Processing
6.2.4. Real-time analytics in Azure
Azure Stream Analytics is a platform-as-a-service (PaaS) solution for defining streaming operations that ingest data from a streaming source, perform a perpetual query, and output the results.
Spark Structured Streaming is an open-source library that lets you build complicated streaming solutions using Apache Spark-based services like Azure Synapse Analytics, Azure Databricks, and Azure HDInsight.
Azure Data Explorer is a high-performance database and analytics service intended for ingesting and querying batch or streaming data with a time-series element. It can be utilized as a stand-alone Azure service or as an Azure Synapse Data Explorer runtime in an Azure Synapse Analytics workspace.
6.2.5. Services for stream processing
In order to ingest data for stream processing on Azure, the following services are often used:
6.2.5.1. Azure Event Hubs
It is a data ingestion solution that allows you to manage event data queues and ensure that each event is processed in the correct order and only once.
6.2.5.2. Azure IoT Hub
It is a data intake service similar to Azure Event Hubs, except it's designed specifically for managing event data from Internet of Things (IoT) devices.
6.2.5.3. Azure Data Lake Store Gen 2
A highly scalable storage service that is frequently utilized in batch processing applications but can also be used to stream data.
6.2.5.4. Apache Kafka
It is an open-source data ingestion system that is frequently used in conjunction with Apache Spark. You may set up a Kafka cluster using Azure HDInsight.
6.2.6. Sinks for stream processing
Stream processing output is frequently delivered to the following services:
6.2.6.1. Azure Event Hubs
These are used to queue processed data for later processing.
Used to save the processed results as a file in Azure
6.2.6.2. Azure Data Lake Store Gen 2 or Azure blob storage
Used to save processed results in a database table for querying and analysis using Azure SQL Database, Azure Synapse Analytics, or Azure Databricks.
6.2.6.3. Microsoft Power BI
It is a business intelligence tool that allows users to create real-time data visualizations in reports and dashboards.
6.2.7. Azure Stream Analytics
Azure Stream Analytics is a service that allows you to handle and analyze streaming data in a complicated way. Stream Analytics is used for a variety of purposes, including:
- Data from an Azure event hub, Azure IoT Hub, or Azure Storage blob container is ingested.
- Select, project, and aggregate data values using a query to process the data.
- Write the results to a destination like Azure Data Lake Gen 2, Azure SQL Database, Azure Synapse Analytics, Azure Functions, Azure Event Hub, Microsoft Power BI, or something else.
6.2.8. Apache Spark on Azure
Apache Spark is a distributed processing framework for large scale data analytics. Used on Azure with these services: Azure Synapse Analytics, Azure Databricks, Azure HDInsight
Spark allows you to run code (often written in Python, Scala, or Java) in parallel across numerous cluster nodes, allowing you to process massive amounts of data quickly. Both batch and stream processing are possible with Spark.
To process streaming data on Spark, you can use the Spark Structured Streaming library, which provides an application programming interface (API) for ingesting, processing, and outputting results from perpetual streams of data.
6.2.9. Bonus, Delta Lake
Delta Lake is an open-source storage layer that extends data lake storage with transactional consistency, schema enforcement, and other typical data warehousing features. It may also be used in Spark to construct relational tables for batch and stream processing, and it unifies storage for streaming and batch data. A Delta Lake table can be used as a streaming source for real-time data queries or as a sink for writing a stream of data when used for stream processing.
Delta Lake is supported by the Spark runtimes in Azure Synapse Analytics and Azure Databricks.
When you need to abstract batch and stream processed data in a data lake behind a relational schema for SQL-based querying and analysis, Delta Lake paired with Spark Structured Streaming is a good solution.
6.2.10. Azure Data Explorer
Azure Data Explorer is a stand-alone Azure tool that helps you analyze data quickly. The service can be used as an output for evaluating massive volumes of data from a variety of sources, including websites, applications, IoT devices, and more. By sending Azure Stream Analytics logs to Azure Data Explorer, you can combine the low latency alert handling of Stream Analytics with the deep investigation capabilities of Data Explorer. The service is now available as a runtime in Azure Synapse Analytics as Azure Synapse Data Explorer, allowing you to create and manage analytical solutions that mix SQL, Spark, and Data Explorer analytics in a single workspace.
6.2.10.1. Kusto Query Language (KQL)
You can use Kusto Query Language (KQL) to query Data Explorer tables, which is a language that is expressly intended for quick read performance – especially with telemetry data that includes a timestamp property.
The simplest KQL query is simply a table name, in which case the query returns all of the table's contents. The following query
| Kusto | |
|---|---|
| YayaLogs |
To filter, sort, aggregate, and return (project) certain columns, you can add clauses to a Kusto query. A | character precedes each clause. The following query, for example, gives the StartTime, EventType, and Message fields from the YayaEvents table for errors logged after April 08, 2001.
YayaLogs| where StartTime > datetime(2001-04-08) | where EventType == 'Error'| project StartTime, EventType , Message6.3. Data Visualization
Definition: The representation of information in the form of a chart, diagram, picture, etc.
6.3.1. Microsoft Power BI
Microsoft Power BI is a suite of tools and services that data analysts can use to build interactive data visualizations for business users to consume.
6.3.1.1. Workflow
A typical workflow for developing a data visualization solution begins with Power BI Desktop, a Microsoft Windows application that allows you to import data from a variety of sources, combine and organize the data in an analytics data model, and create reports with interactive visualizations of the data.
6.3.2. Core concepts of data modeling
Analytical models allow you to organize data so that it can be analyzed. Models are defined by the quantitative values you wish to analyze or report (known as measures) and the entities by which you want to aggregate them, and they are based on connected tables of data (known as dimensions).
6.3.2.1. Tables And Schema
Dimension tables represent the entities by which you want to aggregate numeric measures – for example product or customer. Each entity is represented by a row with a unique key value.
6.3.2.2. Attribute Hierarchies
Enable you to quickly drill-up or drill-down to find aggregated values at different levels in a hierarchical dimension.
6.3.2.3. Analytical modeling in Power BI
You can use Power BI to define an analytical model from tables of data, which can be imported from one or more data source.
6.3.3. Data Visualization Concerns
You can utilize a model to generate data visualizations that can be included in a report after you've created it.
There are many different types of data visualization, some of which are more widely used and others which are more specialized. Power BI comes with a large number of pre-built visualizations that may be supplemented with custom and third-party visualizations. The rest of this lesson goes over some popular data visualizations, although it's far from exhaustive.
Tables and text: Tables and text are often the simplest way to communicate data.
Bar and column charts: are a good way to visually compare numeric values for discrete categories.
Line charts: can also be used to compare categorized values and are useful when you need to examine trends, often over time.
Pie charts: Pie charts are often used in business reports to visually compare categorized values as proportions of a total.
Scatter plots: Scatter plots are useful when you want to compare two numeric measures and identify a relationship or correlation between them.
Maps: are a great way to visually compare values for different geographic areas or locations.
Interactive Reports in Power BI:
The visual elements for relevant data in a report in Power BI are automatically linked and provide interactivity. Selecting a single category in one visualization, for example, will automatically filter and emphasize that category in related visualizations throughout the report. The city of Seattle has been selected in the Sales by City and Category column chart in the image above, and the other visualizations have been filtered to only show figures for Seattle.
Because Power Bi is such a key aspect of the Microsoft Power Platform, it will be covered in depth in The Power Platform Certification (PL-900).
“If we have data, let’s look at data. If all we have are opinions, let’s go with mine.” — Jim Barksdale